
Claude Codeで自動化パイプラインを構築するとき、「AIの応答が毎回同じ構造で返ってくる」ことは非常に重要です。--json-schema オプションを使えば、Claudeの応答を事前に定義したJSONスキーマに準拠させることができます。これにより、後続の処理で「想定外の形式が返ってきて壊れる」事態を防げます。
この記事では、スキーマの定義方法から実際にREADME情報を構造化して取得するところまでを解説します。
Claude Codeのprintモード(claude -p)と --output-format json を使ったことがある前提で進めます。
printモードやoutput-formatについて詳しく知りたい人は、【Claude Code】の出力形式を使いこなす――text・json・stream-jsonの違いと実践 を参考にしてください。
–json-schemaとは何か
--json-schema は、Claudeの応答内容(result フィールド)を指定したJSON Schemaに準拠させるオプションです。printモード(-p)専用で、--output-format json と組み合わせて使います。
たとえば「タイトル・説明・関数一覧・使い方」という4つのフィールドを必ず含むJSONが欲しいとき、スキーマで構造を定義しておけば、Claudeはその構造に従って回答を生成します。
スキーマを定義する
まず、README用の情報を構造化するスキーマファイルを作成します。スキーマとは、「Claudeに返してほしいJSONの形」を定義する設計図のようなものです。どんなフィールド(項目)が必要で、それぞれがどんなデータ型かを指定します。
以下のコマンドを実行すると、作業ディレクトリに readme_schema.json というファイルが作成されます。このファイルは、次のセクションで実際にClaude Codeのコマンドに渡して使います。
cat << 'SCHEMA' > readme_schema.json
{
"type": "object",
"required": ["title", "description", "functions", "usage"],
"properties": {
"title": {
"type": "string",
"description": "プロジェクトのタイトル"
},
"description": {
"type": "string",
"description": "プロジェクトの概要説明"
},
"functions": {
"type": "array",
"items": {
"type": "object",
"required": ["name", "description", "parameters", "return_type"],
"properties": {
"name": { "type": "string" },
"description": { "type": "string" },
"parameters": { "type": "string" },
"return_type": { "type": "string" }
}
}
},
"usage": {
"type": "string",
"description": "使用方法の説明"
}
}
}
SCHEMA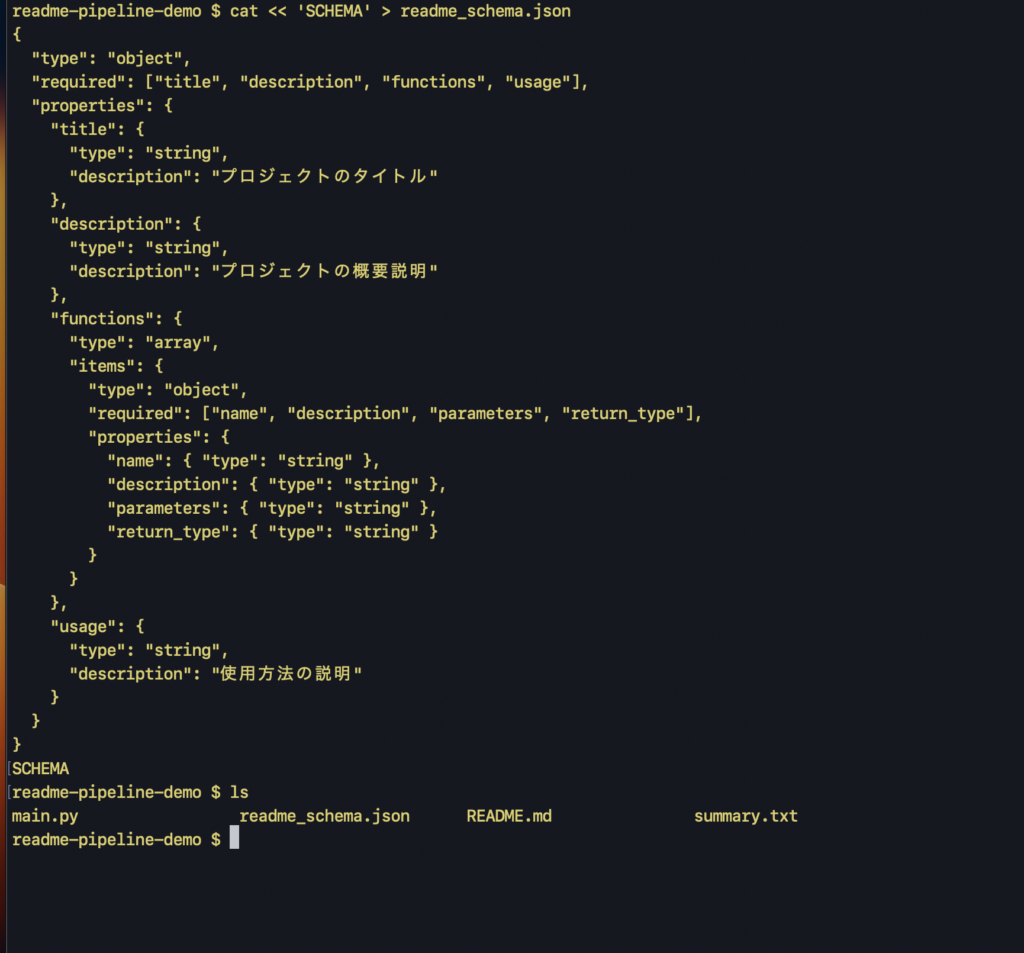
ここではまだスキーマファイルを準備しただけです。実際にこのスキーマを使ってClaude Codeを実行する方法は、次のセクションで解説します。
ポイントは required フィールドです。必須フィールドを明示的に required 配列に含めることで、Claudeが一部のフィールドを省略することを防ぎます。required の設定を忘れると、欲しいフィールドが返ってこない可能性があるので注意してください。
スキーマを使ってREADME情報を取得する
作成したスキーマを --json-schema オプションに渡します。
claude -p "main.pyを解析して、README用の情報をJSON形式で出力してください" \
--output-format json \
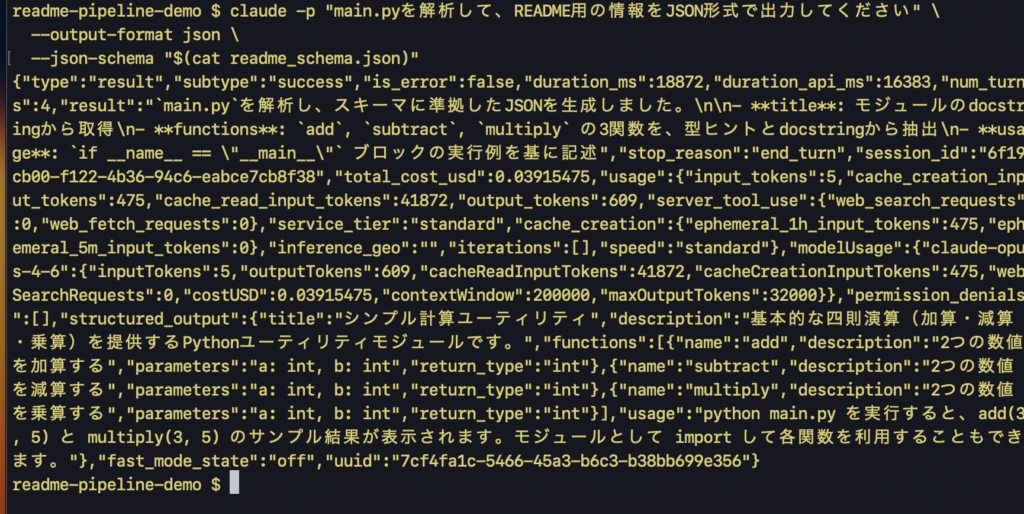
--json-schema "$(cat readme_schema.json)"出力例(structured_output フィールドにスキーマに準拠したJSONが格納されます):
{
"type": "result",
"subtype": "success",
"is_error": false,
"duration_ms": 18872,
"duration_api_ms": 16383,
"num_turns": 4,
"result": "`main.py`を解析し、スキーマに準拠したJSONを生成しました。\n\n- **title**: モジュールのdocstringから取得\n- **functions**: `add`, `subtract`, `multiply` の3関数を、型ヒントとdocstringから抽出\n- **usage**: `if __name__ == \"__main__\"` ブロックの実行例を基に記述",
"stop_reason": "end_turn",
"session_id": "6f19cb00-f122-4b36-94c6-eabce7cb8f38",
"total_cost_usd": 0.03915475,
"usage": {
"input_tokens": 5,
"cache_creation_input_tokens": 475,
"cache_read_input_tokens": 41872,
"output_tokens": 609,
"server_tool_use": {
"web_search_requests": 0,
"web_fetch_requests": 0
},
"service_tier": "standard",
"cache_creation": {
"ephemeral_1h_input_tokens": 475,
"ephemeral_5m_input_tokens": 0
},
"inference_geo": "",
"iterations": [],
"speed": "standard"
},
"modelUsage": {
"claude-opus-4-6": {
"inputTokens": 5,
"outputTokens": 609,
"cacheReadInputTokens": 41872,
"cacheCreationInputTokens": 475,
"webSearchRequests": 0,
"costUSD": 0.03915475,
"contextWindow": 200000,
"maxOutputTokens": 32000
}
},
"permission_denials": [],
"structured_output": {
"title": "シンプル計算ユーティリティ",
"description": "基本的な四則演算(加算・減算・乗算)を提供するPythonユーティリティモジュールです。",
"functions": [
{
"name": "add",
"description": "2つの数値を加算する",
"parameters": "a: int, b: int",
"return_type": "int"
},
{
"name": "subtract",
"description": "2つの数値を減算する",
"parameters": "a: int, b: int",
"return_type": "int"
},
{
"name": "multiply",
"description": "2つの数値を乗算する",
"parameters": "a: int, b: int",
"return_type": "int"
}
],
"usage": "python main.py を実行すると、add(3, 5) と multiply(3, 5) のサンプル結果が表示されます。モジュールとして import して各関数を利用することもできます。"
},
"fast_mode_state": "off",
"uuid": "7cf4fa1c-5466-45a3-b6c3-b38bb699e356"
}structured_outputを取り出す
スキーマに準拠した構造化データは structured_output フィールドに入っています。jq で取り出して整形しましょう。
claude -p "main.pyを解析して、README用の情報をJSON形式で出力してください" --output-format json --json-schema "$(cat readme_schema.json)" | jq '.structured_output'出力例:
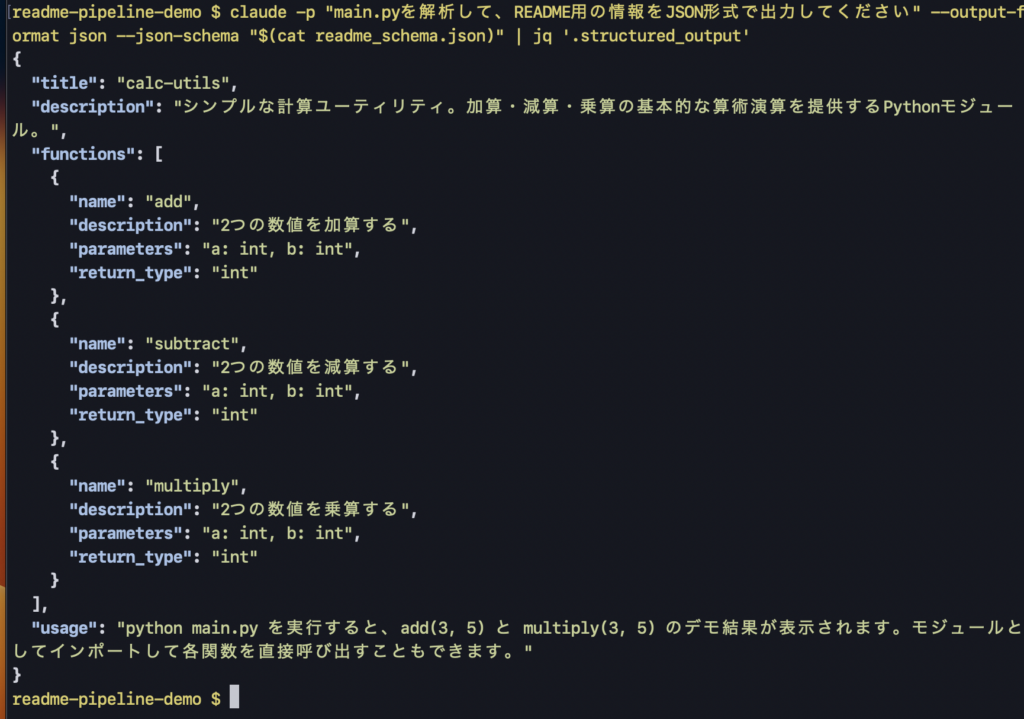
{
"title": "calc-utils",
"description": "シンプルな計算ユーティリティ。加算・減算・乗算の基本的な算術演算を提供するPythonモジュール。",
"functions": [
{
"name": "add",
"description": "2つの数値を加算する",
"parameters": "a: int, b: int",
"return_type": "int"
},
{
"name": "subtract",
"description": "2つの数値を減算する",
"parameters": "a: int, b: int",
"return_type": "int"
},
{
"name": "multiply",
"description": "2つの数値を乗算する",
"parameters": "a: int, b: int",
"return_type": "int"
}
],
"usage": "python main.py を実行すると、add(3, 5) と multiply(3, 5) のデモ結果が表示されます。モジュールとしてインポートして各関数を直接呼び出すこともできます。"
}きれいに構造化されたJSONが得られました。この構造が毎回保証されるので、後続のスクリプトで安心して各フィールドを参照できます。
構造化JSONからREADME.mdを自動生成する
取得した構造化JSONを使って、README.mdを自動生成するスクリプトを作ってみましょう。
cat << 'SCRIPT' > generate_readme.sh
#!/bin/bash
set -euo pipefail
SCHEMA='{"type":"object","required":["title","description","functions","usage"],"properties":{"title":{"type":"string"},"description":{"type":"string"},"functions":{"type":"array","items":{"type":"object","required":["name","description","parameters","return_type"],"properties":{"name":{"type":"string"},"description":{"type":"string"},"parameters":{"type":"string"},"return_type":{"type":"string"}}}},"usage":{"type":"string"}}}'
echo "=== README生成パイプライン ==="
echo "Step 1: コード解析とJSON生成..."
result=$(claude -p "このリポジトリのコードを解析して、README用の情報をJSON形式で出力してください" \
--output-format json \
--json-schema "$SCHEMA" \
--max-budget-usd 0.10)
is_error=$(echo "$result" | jq -r '.is_error')
cost=$(echo "$result" | jq -r '.total_cost_usd')
echo " コスト: \$${cost}"
if [ "$is_error" = "true" ]; then
echo " エラー: $(echo "$result" | jq -r '.result')"
exit 1
fi
echo "Step 2: JSONからREADME.mdを生成..."
readme_json=$(echo "$result" | jq '.structured_output')
title=$(echo "$readme_json" | jq -r '.title')
description=$(echo "$readme_json" | jq -r '.description')
usage=$(echo "$readme_json" | jq -r '.usage')
{
echo "# ${title}"
echo ""
echo "${description}"
echo ""
echo "## 関数一覧"
echo ""
echo "| 関数名 | 説明 | パラメータ | 戻り値 |"
echo "|--------|------|-----------|--------|"
echo "$readme_json" | jq -r '.functions[] | "| \(.name) | \(.description) | \(.parameters) | \(.return_type) |"'
echo ""
echo "## 使い方"
echo ""
echo "${usage}"
} > README.md
echo "Step 3: 完了!"
echo " 生成ファイル: README.md"
cat README.md
SCRIPT
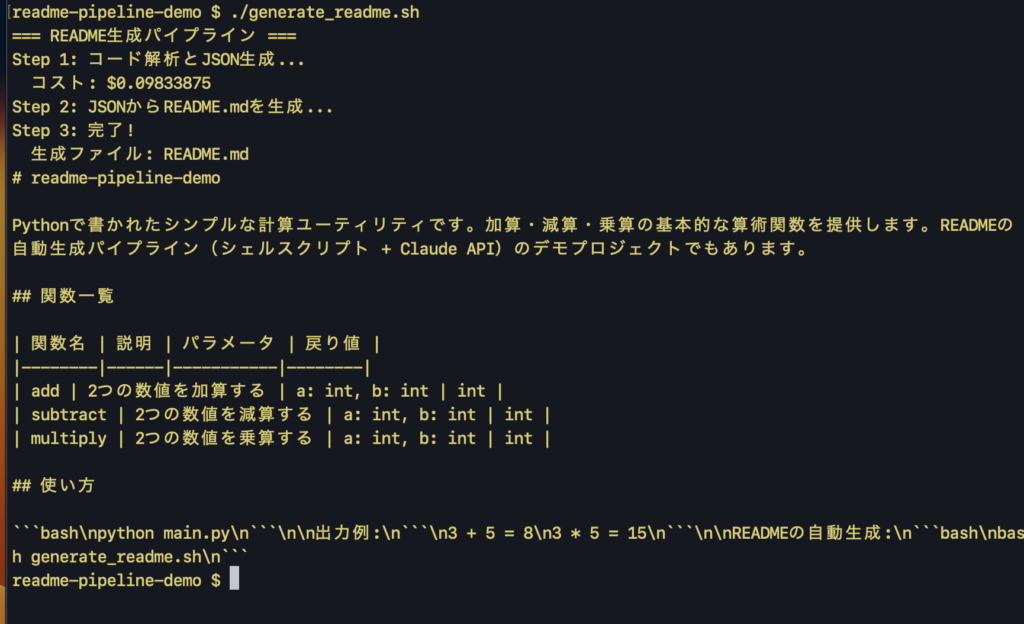
chmod +x generate_readme.sh実行すると、コード解析から構造化JSON取得、README生成までが一気に完了します。
./generate_readme.sh出力例:
スキーマ設計のコツ
- requiredは必ず設定する: 省略するとClaudeがフィールドを返さない可能性がある
- descriptionを各プロパティに書く: Claudeがフィールドの意図を正確に理解し、適切な内容を生成してくれる
- ネストは浅めに保つ: 深すぎるネストはスキーマが複雑になり、後続処理も煩雑になる
次に試してみよう
readme_schema.json に installation(インストール手順)、license(ライセンス情報)、dependencies(依存関係の配列)を追加して、より充実したREADMEを生成してみてください。フィールドを増やすほど、構造化出力の威力が実感できるはずです。
さらに深く学びたい方へ
Claude Codeの Skills・MCP・Agent・Hooks・Plugin を体系的に学べる有料教材を Zenn で公開しています。
Claude Code 実践ガイド(Zenn Book)





