
Claude Codeのセッション管理には、--continue や --resume だけでなく、パイプラインで真価を発揮する --session-id と --fork-session というオプションがあります。セッションIDを事前に固定して段階的にパイプラインを実行する方法と、セッションを安全に分岐して実験的な変更を試す方法を解説します。
前提知識
--continue/--resumeによるセッション継続・再開を理解していること- printモード(
claude -p)と--output-format jsonを使えること
前提知識について詳しく知りたい人は以下の記事を参考にしてください。
【Claude Code】printモード入門|パイプ連携とスクリプト活用の基本
【Claude Code】セッション管理入門──–continueと–resumeの違いを理解しよう
サンプルプロジェクトの準備
この記事では、これまでの記事で使用してきた readme-pipeline-demo プロジェクトを引き続き使います。まだ作成していない場合は、以下のコマンドで準備してください。
mkdir -p ~/readme-pipeline-demo
cd ~/readme-pipeline-demo
git initcat << 'EOF' > main.py
"""シンプルな計算ユーティリティ"""
def add(a: int, b: int) -> int:
"""2つの数値を加算する"""
return a + b
def subtract(a: int, b: int) -> int:
"""2つの数値を減算する"""
return a - b
def multiply(a: int, b: int) -> int:
"""2つの数値を乗算する"""
return a * b
if __name__ == "__main__":
print(f"3 + 5 = {add(3, 5)}")
print(f"3 - 5 = {subtract(3, 5)}")
print(f"3 * 5 = {multiply(3, 5)}")
EOF–session-idでセッションIDを固定する
パイプラインではセッションIDを事前に決めておくことで、段階的な処理の管理が容易になります。まず uuidgen コマンドでUUID形式のIDを生成します。
SESSION_ID=$(uuidgen | tr '[:upper:]' '[:lower:]')
echo "セッションID: $SESSION_ID"
このIDを使って、段階的にパイプラインを実行します。各ステップで同じセッションを共有するため、Claudeは前のステップの分析結果を覚えた状態で次の指示に取り組めます。
Step 1: コード構造の分析(セッション開始)
claude -p "このリポジトリのコード構造を分析してください。各関数の目的、引数、戻り値を把握してください。" --session-id "$SESSION_ID" --output-format json | jq -r '.result'Step 1ではまだ分析だけです。--session-id を指定しているので、このセッションIDで会話が記録されます。
Step 2: 前回の分析を踏まえて関数の詳細を抽出(同じセッションを継続)
claude -p --resume "$SESSION_ID" "前回の分析を踏まえて、各関数の詳細なドキュメントをテキストで出力してください。ファイルは編集しないでください。" --output-format json | jq -r '.result'Step 2では --resume "$SESSION_ID" で前回のセッションを継続しています。Claudeは Step 1 の分析結果を踏まえた上で回答するため、より精度の高いドキュメントが生成されます。
Step 3: 前回までの結果をまとめてREADMEを生成
claude -p --resume "$SESSION_ID" "これまでの分析結果をまとめて、完全なREADME.mdの内容を出力してください" --output-format json | jq -r '.result' > README.md
cat README.md
Step 3 で最終的なREADME.mdを生成しました。3段階を踏むことで、1回の指示で生成するよりも充実した内容になります。
このパターンのメリットは3つあります。
- コンテキストの蓄積: 各ステップでコンテキストが蓄積され、後のステップほど質の高い出力が得られる
- 部分的な再実行: セッションIDが分かっているため、途中で失敗してもそのステップだけ再実行できる
- デバッグが容易: ログにセッションIDを記録することで、後から調査・デバッグがしやすい
注意点: セッションIDに無効な形式(UUIDでない文字列)を指定するとエラーになります。必ず uuidgen コマンドで正しい形式のUUIDを使用してください。
–fork-sessionでセッションを分岐する
--fork-session は --resume または --continue と組み合わせて使います。元のセッションを変更せずに、分岐した新しいセッションで作業を続けられます。
イメージとしては、Gitのブランチに近い概念です。
# 元のセッションから分岐して実験的な変更を試す
claude --resume "$SESSION_ID" --fork-sessionこれにより、元のセッション($SESSION_ID)はそのまま残り、新しいセッションIDが割り当てられます。元の会話履歴をコピーした状態で開始され、分岐先での変更は元のセッションに影響しません。
実践例: 異なるスタイルのREADMEを比較生成
先ほどの3段階パイプラインで蓄積した分析結果から、異なるスタイルのREADMEを比較生成してみましょう。元のセッションから2回分岐して、それぞれ別の指示を出します。
パターンA: 技術者向けREADME(元のセッションから分岐)
claude -p --resume "$SESSION_ID" --fork-session "これまでの分析結果を元に、技術者向けの詳細なREADMEを生成してください。API仕様、型情報、エラーハンドリングを重視してください。" --output-format json | jq -r '.result' > README_technical.md
echo "=== 技術者向けREADME ==="
cat README_technical.md
パターンB: 初心者向けREADME(元のセッションから再度分岐)
claude -p --resume "$SESSION_ID" --fork-session "これまでの分析結果を元に、プログラミング初心者向けのやさしいREADMEを生成してください。専門用語を避け、使い方の具体例を多めにしてください。" --output-format json | jq -r '.result' > README_beginner.md
echo "=== 初心者向けREADME ==="
cat README_beginner.md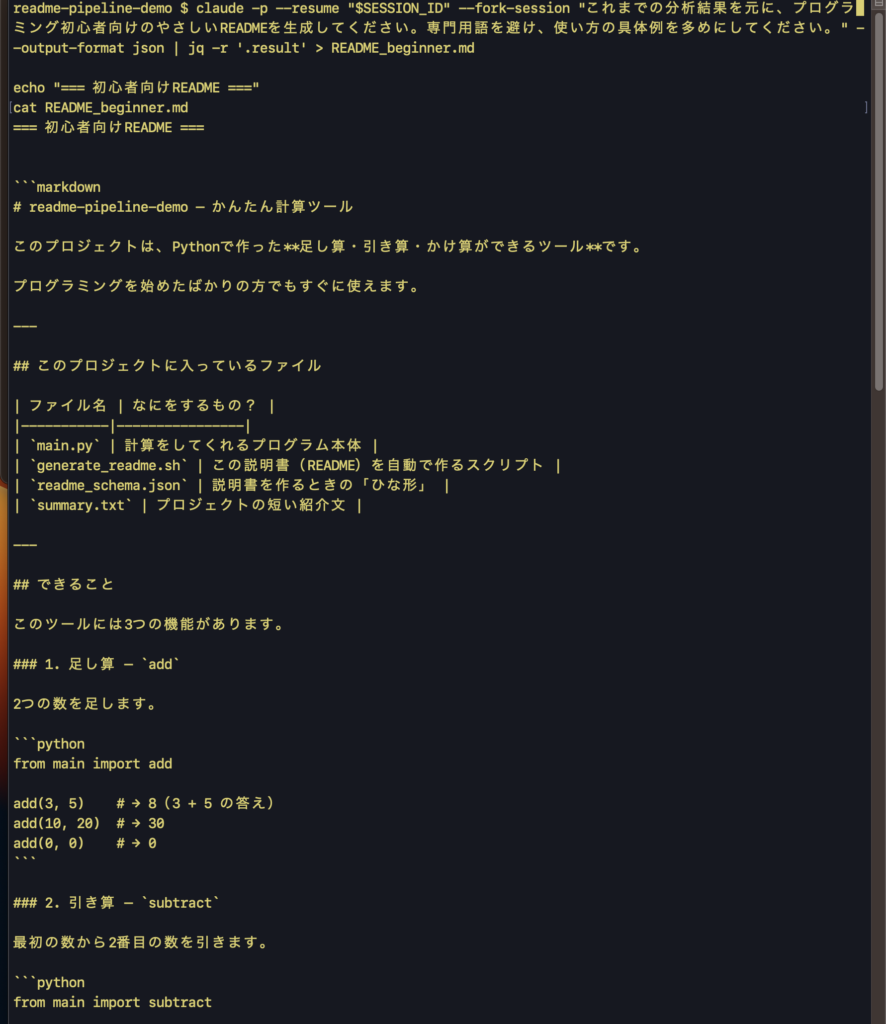
ポイントは、どちらも --resume "$SESSION_ID" で同じ元のセッションから分岐していることです。パターンAの分岐がパターンBに影響することはありません。元のセッションを「正」として保持しつつ、複数の改善案を並行して試せるのがメリットです。
生成された2つのREADMEを見比べて、良い部分を採用するといった使い方ができます。
セッション管理付きパイプラインスクリプト
ここまでの知識を組み合わせた実践的なパイプラインスクリプトを作ってみましょう。--session-id でセッションIDを固定し、--json-schema で構造化出力を得て、シェルスクリプトでREADME.mdを組み立てます。
cat << 'SCRIPT' > generate_readme_v2.sh
#!/bin/bash
set -euo pipefail
SESSION_ID=$(uuidgen | tr '[:upper:]' '[:lower:]')
echo "=== README生成パイプライン v2 ==="
echo "セッションID: $SESSION_ID"
SCHEMA='{"type":"object","required":["title","description","functions","usage"],"properties":{"title":{"type":"string"},"description":{"type":"string"},"functions":{"type":"array","items":{"type":"object","required":["name","description","parameters","return_type"],"properties":{"name":{"type":"string"},"description":{"type":"string"},"parameters":{"type":"string"},"return_type":{"type":"string"}}}},"usage":{"type":"string"}}}'
# Step 1: コード解析 & 構造化データ生成
echo ""
echo "Step 1: コード解析 & 構造化データの生成..."
result=$(claude -p "main.pyを解析して、README用の情報をJSON形式で出力してください" --output-format json --json-schema "$SCHEMA" --session-id "$SESSION_ID" --max-budget-usd 0.10)
echo " コスト: \$$(echo "$result" | tr '\n' ' ' | jq -r '.total_cost_usd')"
is_error=$(echo "$result" | tr '\n' ' ' | jq -r '.is_error')
if [ "$is_error" = "true" ]; then
echo " エラー: $(echo "$result" | tr '\n' ' ' | jq -r '.result')"
echo " セッションID ${SESSION_ID} を使って調査してください"
exit 1
fi
# Step 2: README組み立て
echo "Step 2: README.md生成..."
readme_json=$(echo "$result" | tr '\n' ' ' | jq '.structured_output')
title=$(echo "$readme_json" | jq -r '.title')
description=$(echo "$readme_json" | jq -r '.description')
usage=$(echo "$readme_json" | jq -r '.usage')
{
echo "# ${title}"
echo ""
echo "${description}"
echo ""
echo "## 関数一覧"
echo ""
echo "| 関数名 | 説明 | パラメータ | 戻り値 |"
echo "|--------|------|-----------|--------|"
echo "$readme_json" | jq -r '.functions[] | "| \(.name) | \(.description) | \(.parameters) | \(.return_type) |"'
echo ""
echo "## 使い方"
echo ""
echo "${usage}"
} > README.md
echo ""
echo "=== 完了 ==="
echo " セッションID: $SESSION_ID"
echo " 出力: README.md"
cat README.md
SCRIPT
chmod +x generate_readme_v2.sh実行してみましょう。
./generate_readme_v2.sh出力例:
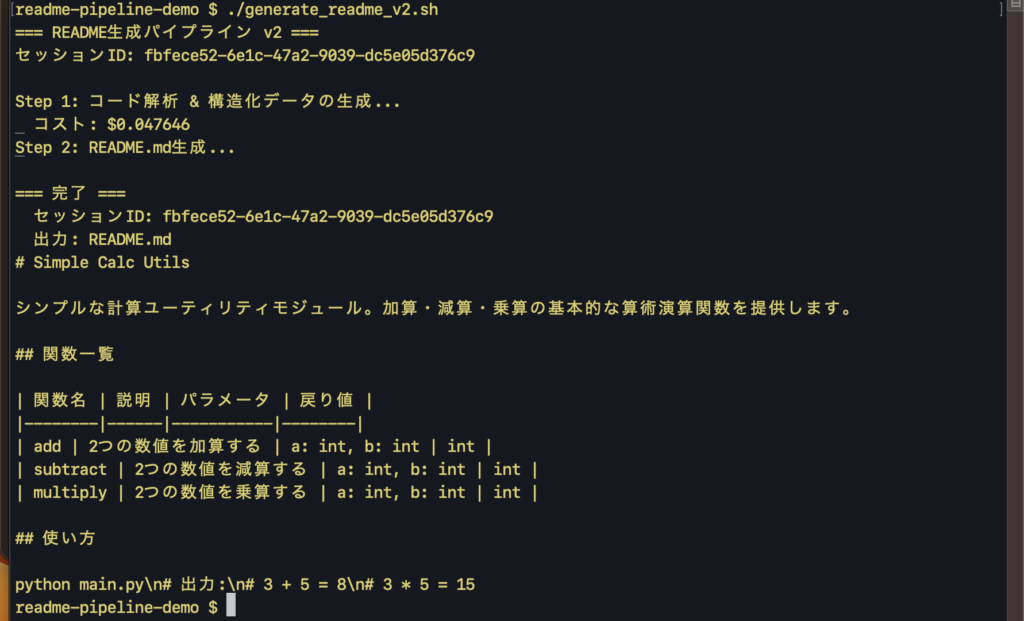
--session-id でIDを固定しているため、スクリプト実行後に claude --resume <セッションID> で該当セッションに戻って対話モードで調査・追加指示ができます。
セッション戦略まとめ
| 用途 | 推奨オプション | 使いどころ |
|---|---|---|
| 直前の作業を再開 | --continue | 対話モードで中断した作業の続き |
| 過去セッションに戻る | --resume ID | 特定の作業に戻りたいとき |
| パイプラインでID管理 | --session-id + --resume | スクリプトで段階的に処理を実行 |
| 安全に実験・比較 | --fork-session | 異なるアプローチを並行して試す |
| CI/CDでセッション不要 | --no-session-persistence | 使い捨ての自動化処理 |
次に試してみよう
generate_readme_v2.shを自分のプロジェクトで実行し、Phase 1→2→3 の各ステップでコストと出力内容がどう変わるか確認してみましょう--fork-sessionで同じ解析結果から「日本語README」と「英語README」を生成し、比較してみましょう
さらに深く学びたい方へ
Claude Codeの Skills・MCP・Agent・Hooks・Plugin を体系的に学べる有料教材を Zenn で公開しています。
Claude Code 実践ガイド(Zenn Book)





